Note
This tutorial can be used interactively with Google Colab! You can also click here to run the Jupyter notebook locally.

Matrix Multiply Blocking¶
Author: Thierry Moreau
This tutorial provides an overview on how to use TVM to map matrix multiplication efficiently on the VTA design. We recommend covering the Simple Matrix Multiply tutorial first.
In this tutorial, we will demonstrate TVM schedule optimizations to break large neural network operators down onto smaller blocks to achieve computation within limited hardware accelerator resources.
RPC Setup¶
We start by programming the Pynq’s FPGA and building its RPC runtime.
from __future__ import absolute_import, print_function
import os
import tvm
from tvm import te
import vta
import numpy as np
from tvm import rpc
from tvm.contrib import utils
from vta.testing import simulator
# Load VTA parameters from the 3rdparty/vta-hw/config/vta_config.json file
env = vta.get_env()
# We read the Pynq RPC host IP address and port number from the OS environment
host = os.environ.get("VTA_RPC_HOST", "192.168.2.99")
port = int(os.environ.get("VTA_RPC_PORT", "9091"))
# We configure both the bitstream and the runtime system on the Pynq
# to match the VTA configuration specified by the vta_config.json file.
if env.TARGET == "pynq":
# Make sure that TVM was compiled with RPC=1
assert tvm.runtime.enabled("rpc")
remote = rpc.connect(host, port)
# Reconfigure the JIT runtime
vta.reconfig_runtime(remote)
# Program the FPGA with a pre-compiled VTA bitstream.
# You can program the FPGA with your own custom bitstream
# by passing the path to the bitstream file instead of None.
vta.program_fpga(remote, bitstream=None)
# In simulation mode, host the RPC server locally.
elif env.TARGET in ["sim", "tsim"]:
remote = rpc.LocalSession()
Computation Declaration¶
As a first step, we need to describe our matrix multiplication computation.
We define the matrix multiplication as the computation one would find in a
fully connected layer, defined by its batch size, input channels, and output
channels.
These have to be integer multiples of the VTA tensor shape:
BATCH, BLOCK_IN, and BLOCK_OUT respectively.
We’ve added extra operators to the matrix multiplication that apply shifting and clipping to the output in order to mimic a fixed-point matrix multiplication followed by a rectified linear activation. We describe the TVM dataflow graph of the fully connected layer below:
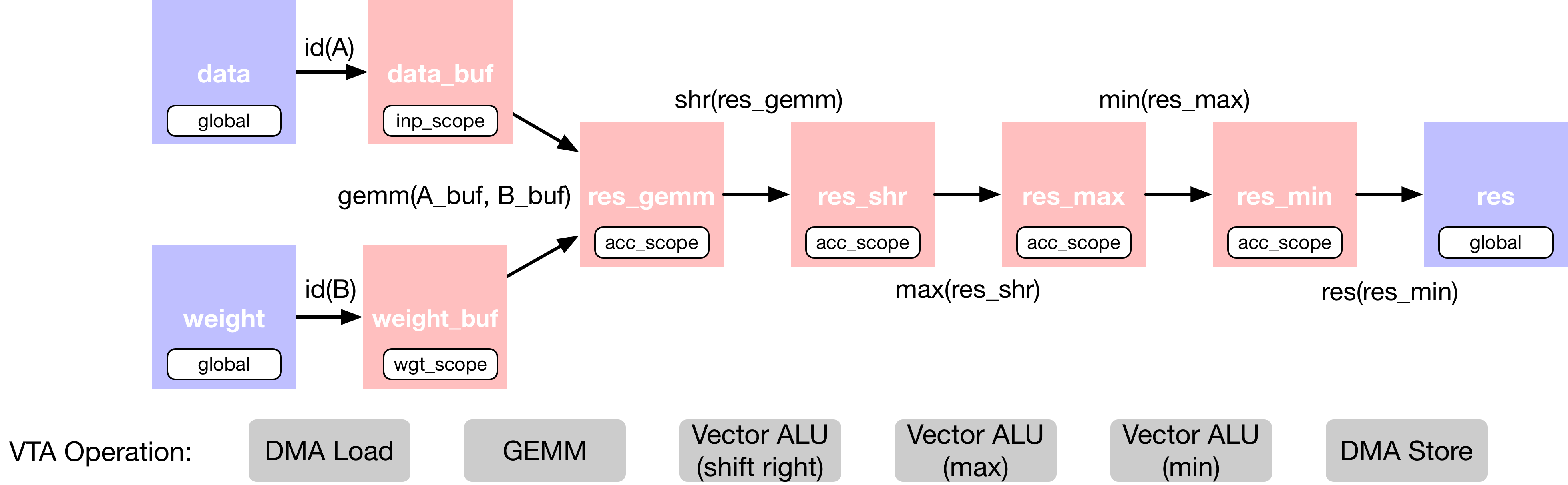
This computation is intentionally too large to fit onto VTA’s on-chip buffers all at once. Therefore in the scheduling phase we’ll rely on computation blocking strategies to break the computation down into manageable chunks.
# Fully connected layer dimensions: 1024 x 1024
batch_size = 1
in_channels = 1024
out_channels = 1024
assert batch_size % env.BATCH == 0
assert in_channels % env.BLOCK_IN == 0
assert out_channels % env.BLOCK_OUT == 0
# Let's derive the tiled input tensor shapes
data_shape = (batch_size // env.BATCH, in_channels // env.BLOCK_IN, env.BATCH, env.BLOCK_IN)
weight_shape = (
out_channels // env.BLOCK_OUT,
in_channels // env.BLOCK_IN,
env.BLOCK_OUT,
env.BLOCK_IN,
)
output_shape = (batch_size // env.BATCH, out_channels // env.BLOCK_OUT, env.BATCH, env.BLOCK_OUT)
num_ops = in_channels * out_channels * batch_size * 2
# Reduction axes
ic = te.reduce_axis((0, in_channels // env.BLOCK_IN), name="ic")
ic_tns = te.reduce_axis((0, env.BLOCK_IN), name="ic_tns")
# Input placeholder tensors
data = te.placeholder(data_shape, name="data", dtype=env.inp_dtype)
weight = te.placeholder(weight_shape, name="weight", dtype=env.wgt_dtype)
# Copy buffers
data_buf = te.compute(data_shape, lambda *i: data(*i), "data_buf")
weight_buf = te.compute(weight_shape, lambda *i: weight(*i), "weight_buf")
# Declare matrix multiply computation
res_gemm = te.compute(
output_shape,
lambda bo, co, bi, ci: te.sum(
data_buf[bo, ic, bi, ic_tns].astype(env.acc_dtype)
* weight_buf[co, ic, ci, ic_tns].astype(env.acc_dtype),
axis=[ic, ic_tns],
),
name="res_gem",
)
# Add shift stage for fix-point normalization
res_shr = te.compute(output_shape, lambda *i: res_gemm(*i) >> env.INP_WIDTH, name="res_shr")
# Apply clipping between (0, input max value)
inp_max = (1 << (env.INP_WIDTH - 1)) - 1
res_max = te.compute(output_shape, lambda *i: tvm.te.max(res_shr(*i), 0), "res_max")
res_min = te.compute(output_shape, lambda *i: tvm.te.min(res_max(*i), inp_max), "res_min")
# Apply typecast to input data type before sending results back
res = te.compute(output_shape, lambda *i: res_min(*i).astype(env.inp_dtype), name="res")
Scheduling the Computation¶
We’ll look at a set of schedule transformations necessary to map the matrix multiplications onto VTA in an efficient fashion. Those include:
Computation blocking
Lowering to VTA hardware intrinsics
@I.ir_module
class Module:
@T.prim_func
def main(data: T.handle, weight: T.handle, res: T.handle):
T.func_attr({"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True})
data_1 = T.match_buffer(data, (1, 64, 1, 16), "int8")
weight_1 = T.match_buffer(weight, (64, 64, 16, 16), "int8")
res_1 = T.match_buffer(res, (1, 64, 1, 16), "int8")
data_buf = T.allocate([1024], "int8", "global")
weight_buf = T.allocate([1048576], "int8", "global")
res_gem = T.allocate([1024], "int32", "global")
data_buf_1 = T.buffer_decl((1024,), "int8", data=data_buf)
for i1, i3 in T.grid(64, 16):
cse_var_1: T.int32 = i1 * 16 + i3
data_2 = T.buffer_decl((1024,), "int8", data=data_1.data)
data_buf_1[cse_var_1] = data_2[cse_var_1]
weight_buf_1 = T.buffer_decl((1048576,), "int8", data=weight_buf)
for i0, i1, i2, i3 in T.grid(64, 64, 16, 16):
cse_var_2: T.int32 = i0 * 16384 + i1 * 256 + i2 * 16 + i3
weight_2 = T.buffer_decl((1048576,), "int8", data=weight_1.data)
weight_buf_1[cse_var_2] = weight_2[cse_var_2]
res_gem_1 = T.buffer_decl((1024,), "int32", data=res_gem)
for co, ci in T.grid(64, 16):
res_gem_1[co * 16 + ci] = 0
for ic, ic_tns in T.grid(64, 16):
cse_var_3: T.int32 = co * 16 + ci
res_gem_1[cse_var_3] = res_gem_1[cse_var_3] + T.Cast("int32", data_buf_1[ic * 16 + ic_tns]) * T.Cast("int32", weight_buf_1[co * 16384 + ic * 256 + ci * 16 + ic_tns])
res_gem_2 = T.buffer_decl((1024,), "int32", data=res_gem)
for i1, i3 in T.grid(64, 16):
cse_var_4: T.int32 = i1 * 16 + i3
res_gem_2[cse_var_4] = T.shift_right(res_gem_1[cse_var_4], 8)
res_gem_3 = T.buffer_decl((1024,), "int32", data=res_gem)
for i1, i3 in T.grid(64, 16):
cse_var_5: T.int32 = i1 * 16 + i3
res_gem_3[cse_var_5] = T.max(res_gem_2[cse_var_5], 0)
res_gem_4 = T.buffer_decl((1024,), "int32", data=res_gem)
for i1, i3 in T.grid(64, 16):
cse_var_6: T.int32 = i1 * 16 + i3
res_gem_4[cse_var_6] = T.min(res_gem_3[cse_var_6], 127)
for i1, i3 in T.grid(64, 16):
cse_var_7: T.int32 = i1 * 16 + i3
res_2 = T.buffer_decl((1024,), "int8", data=res_1.data)
res_2[cse_var_7] = T.Cast("int8", res_gem_4[cse_var_7])
Blocking the Computation¶
The matrix multiplication is by default too large for activations or weights to fit on VTA’s on-chip buffers all at once. We block the (1, 1024) by (1024, 1024) matrix multiplication into smaller (1, 256) by (256, 256) matrix multiplications so the intermediate tensors can fit on the accelerator’s on-chip SRAM. This approach is similar to blocking techniques applied to CPUs and GPUs in order to increase cache hit rate.
We perform blocking along each axes (the batch axis being untouched since we are performing singe-batch inference). We also leave the inner-most tensorization axes as-is in order to allow TVM to pattern-match tensorization. We show the outcome of blocking on the computation schedule in the diagram below:
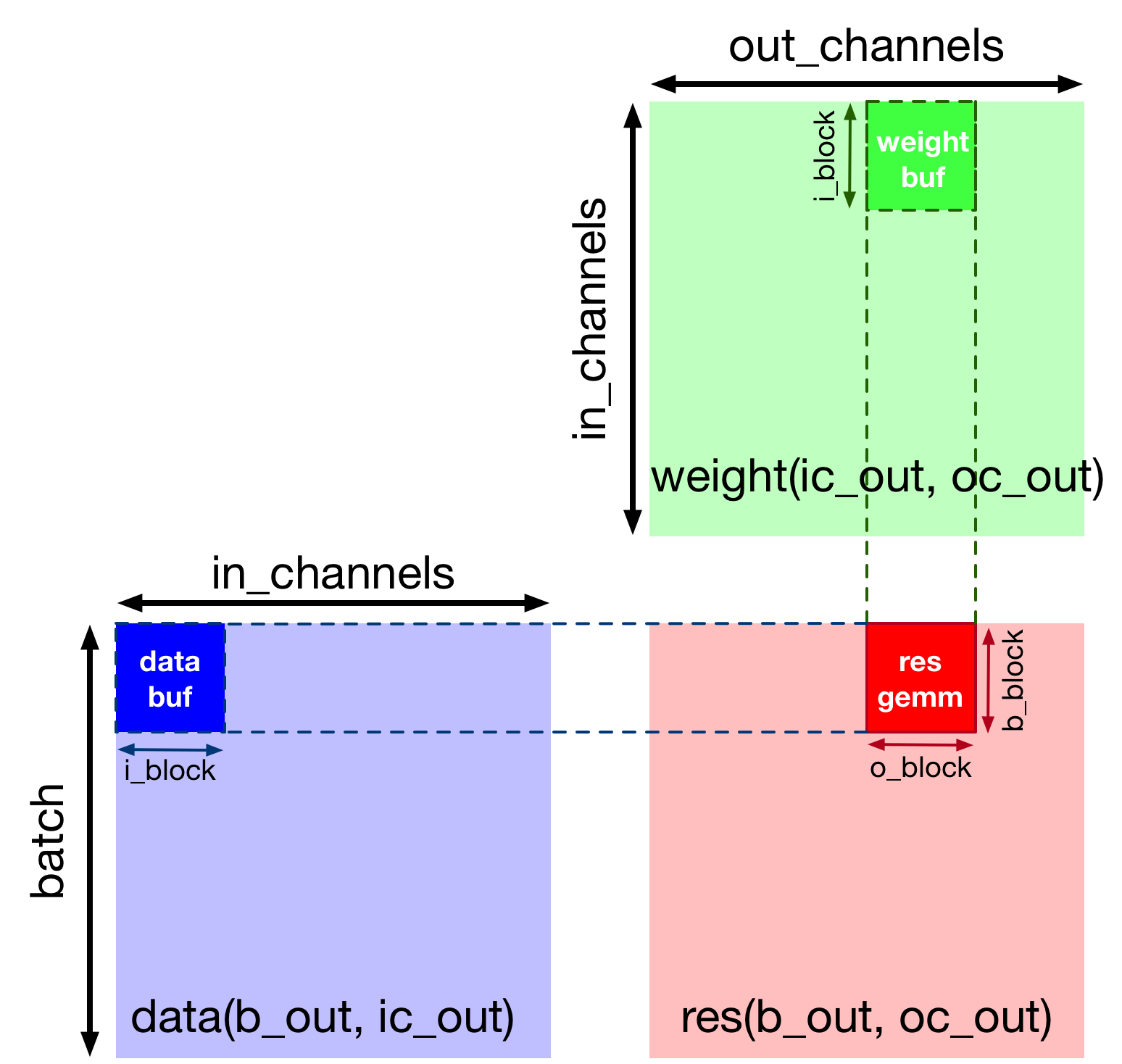
Note
The code after loop splitting and reordering is equivalent to the following pseudo-code. We ignore the batch axis since we are only performing single-batch inference in this example:
for (int oc_out = 0; oc_out < 4; ++oc_out) {
// Initialization loop
for (int oc_inn = 0; oc_inn < 16; ++oc_inn) {
for (int oc_tns = 0; oc_tns < 16; ++oc_tns) {
int j = (oc_out * 16 + oc_inn) * 16 + oc_tns;
C[0][j] = 0;
}
}
for (int ic_out = 0; ic_out < 4; ++ic_out) {
// Block loop
for (int oc_inn = 0; oc_inn < 16; ++oc_inn) {
for (int ic_inn = 0; ic_inn < 16; ++ic_inn) {
// Tensorization loop
for (int oc_tns = 0; oc_tns < 16; ++oc_tns) {
for (int ic_tns = 0; ic_tns < 16; ++ic_tns) {
int i = (ic_out * 16 + ic_inn) * 16 + ic_tns;
int j = (oc_out * 16 + oc_inn) * 16 + oc_tns;
C[0][i] = C[0][i] + A[0][i] * B[j][i];
}
}
}
}
}
}
}
# Let's define tiling sizes (expressed in multiples of VTA tensor shape size)
b_block = 1 // env.BATCH
i_block = 256 // env.BLOCK_IN
o_block = 256 // env.BLOCK_OUT
# Tile the output tensor along the batch and output channel dimensions
# (since by default we are doing single batch inference, the split along
# the batch dimension has no effect)
b, oc, b_tns, oc_tns = s[res].op.axis
b_out, b_inn = s[res].split(b, b_block)
oc_out, oc_inn = s[res].split(oc, o_block)
s[res].reorder(b_out, oc_out, b_inn, oc_inn)
# Move intermediate computation into each output compute tile
s[res_gemm].compute_at(s[res], oc_out)
s[res_shr].compute_at(s[res], oc_out)
s[res_max].compute_at(s[res], oc_out)
s[res_min].compute_at(s[res], oc_out)
# Apply additional loop split along reduction axis (input channel)
b_inn, oc_inn, b_tns, oc_tns = s[res_gemm].op.axis
ic_out, ic_inn = s[res_gemm].split(ic, i_block)
# Reorder axes. We move the ic_out axis all the way out of the GEMM
# loop to block along the reduction axis
s[res_gemm].reorder(ic_out, b_inn, oc_inn, ic_inn, b_tns, oc_tns, ic_tns)
# Let's look at the current TVM schedule after blocking
print(tvm.lower(s, [data, weight, res], simple_mode=True))
@I.ir_module
class Module:
@T.prim_func
def main(data: T.handle, weight: T.handle, res: T.handle):
T.func_attr({"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True})
data_1 = T.match_buffer(data, (1, 64, 1, 16), "int8")
weight_1 = T.match_buffer(weight, (64, 64, 16, 16), "int8")
res_1 = T.match_buffer(res, (1, 64, 1, 16), "int8")
data_buf = T.allocate([1024], "int8", "global")
weight_buf = T.allocate([1048576], "int8", "global")
res_gem = T.allocate([256], "int32", "global")
data_buf_1 = T.buffer_decl((1024,), "int8", data=data_buf)
for i1, i3 in T.grid(64, 16):
cse_var_1: T.int32 = i1 * 16 + i3
data_2 = T.buffer_decl((1024,), "int8", data=data_1.data)
data_buf_1[cse_var_1] = data_2[cse_var_1]
weight_buf_1 = T.buffer_decl((1048576,), "int8", data=weight_buf)
for i0, i1, i2, i3 in T.grid(64, 64, 16, 16):
cse_var_2: T.int32 = i0 * 16384 + i1 * 256 + i2 * 16 + i3
weight_2 = T.buffer_decl((1048576,), "int8", data=weight_1.data)
weight_buf_1[cse_var_2] = weight_2[cse_var_2]
for i1_outer in range(4):
res_gem_1 = T.buffer_decl((256,), "int32", data=res_gem)
for co_init, ci_init in T.grid(16, 16):
res_gem_1[co_init * 16 + ci_init] = 0
for ic_outer, co, ic_inner, ci, ic_tns in T.grid(4, 16, 16, 16, 16):
cse_var_3: T.int32 = co * 16 + ci
res_gem_1[cse_var_3] = res_gem_1[cse_var_3] + T.Cast("int32", data_buf_1[ic_outer * 256 + ic_inner * 16 + ic_tns]) * T.Cast("int32", weight_buf_1[i1_outer * 262144 + co * 16384 + ic_outer * 4096 + ic_inner * 256 + ci * 16 + ic_tns])
res_gem_2 = T.buffer_decl((256,), "int32", data=res_gem)
for i1, i3 in T.grid(16, 16):
cse_var_4: T.int32 = i1 * 16 + i3
res_gem_2[cse_var_4] = T.shift_right(res_gem_1[cse_var_4], 8)
res_gem_3 = T.buffer_decl((256,), "int32", data=res_gem)
for i1, i3 in T.grid(16, 16):
cse_var_5: T.int32 = i1 * 16 + i3
res_gem_3[cse_var_5] = T.max(res_gem_2[cse_var_5], 0)
res_gem_4 = T.buffer_decl((256,), "int32", data=res_gem)
for i1, i3 in T.grid(16, 16):
cse_var_6: T.int32 = i1 * 16 + i3
res_gem_4[cse_var_6] = T.min(res_gem_3[cse_var_6], 127)
for i1_inner, i3 in T.grid(16, 16):
cse_var_7: T.int32 = i1_inner * 16
res_2 = T.buffer_decl((1024,), "int8", data=res_1.data)
res_2[i1_outer * 256 + cse_var_7 + i3] = T.Cast("int8", res_gem_4[cse_var_7 + i3])
Lowering Copies to DMA Transfers¶
Next we set the buffer scopes to the corresponding on-chip VTA SRAM buffers. We move the load loops into the matrix multiply computation loop to stage memory loads such that they fit in the on-chip SRAM buffers. Finally we annotate the load/store loop outer axes with the DMA copy pragma to perform bulk memory transfers on VTA.
# Set scope of SRAM buffers
s[data_buf].set_scope(env.inp_scope)
s[weight_buf].set_scope(env.wgt_scope)
s[res_gemm].set_scope(env.acc_scope)
s[res_shr].set_scope(env.acc_scope)
s[res_min].set_scope(env.acc_scope)
s[res_max].set_scope(env.acc_scope)
# Block data and weight cache reads
s[data_buf].compute_at(s[res_gemm], ic_out)
s[weight_buf].compute_at(s[res_gemm], ic_out)
# Use DMA copy pragma on DRAM->SRAM operations
s[data_buf].pragma(s[data_buf].op.axis[0], env.dma_copy)
s[weight_buf].pragma(s[weight_buf].op.axis[0], env.dma_copy)
# Use DMA copy pragma on SRAM->DRAM operation
# (this implies that these copies should be performed along b_inn,
# or result axis 2)
s[res].pragma(s[res].op.axis[2], env.dma_copy)
Lowering Computation to VTA Compute Intrinsics¶
The last phase is to lower the computation loops down to VTA hardware intrinsics by mapping the matrix multiplication to tensor intrinsics, and mapping the shift, and clipping computation to the vector ALU.
# Apply tensorization over the batch tensor tile axis
s[res_gemm].tensorize(b_tns, env.gemm)
# Add an ALU pragma over the shift and clipping operations
s[res_shr].pragma(s[res_shr].op.axis[0], env.alu)
s[res_min].pragma(s[res_min].op.axis[0], env.alu)
s[res_max].pragma(s[res_max].op.axis[0], env.alu)
# Let's look at the final lowered TVM schedule after lowering memory
# loads/stores down to DMA copy intrinsics, and the computation down to
# VTA compute intrinsics.
print(vta.lower(s, [data, weight, res], simple_mode=True))
@I.ir_module
class Module:
@T.prim_func
def main(data: T.handle, weight: T.handle, res: T.handle):
T.func_attr({"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True})
data_1 = T.match_buffer(data, (1, 64, 1, 16), "int8")
weight_1 = T.match_buffer(weight, (64, 64, 16, 16), "int8")
res_1 = T.match_buffer(res, (1, 64, 1, 16), "int8")
T.tir.vta.coproc_dep_push(3, 2)
for i1_outer in range(4):
vta = T.var("int32")
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_scope", 2):
T.tir.vta.coproc_dep_pop(3, 2)
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_uop_scope", "VTAPushGEMMOp"):
T.call_extern("int32", "VTAUopLoopBegin", 16, 1, 0, 0)
T.tir.vta.uop_push(0, 1, 0, 0, 0, 0, 0, 0)
T.call_extern("int32", "VTAUopLoopEnd")
T.tir.vta.coproc_dep_push(2, 1)
for ic_outer in range(4):
cse_var_1: T.int32 = ic_outer * 16
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_scope", 1):
T.tir.vta.coproc_dep_pop(2, 1)
T.call_extern("int32", "VTALoadBuffer2D", T.tvm_thread_context(T.tir.vta.command_handle()), data_1.data, cse_var_1, 16, 1, 16, 0, 0, 0, 0, 0, 2)
T.call_extern("int32", "VTALoadBuffer2D", T.tvm_thread_context(T.tir.vta.command_handle()), weight_1.data, i1_outer * 1024 + cse_var_1, 16, 16, 64, 0, 0, 0, 0, 0, 1)
T.tir.vta.coproc_dep_push(1, 2)
T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_scope", 2)
T.tir.vta.coproc_dep_pop(1, 2)
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_uop_scope", "VTAPushGEMMOp"):
T.call_extern("int32", "VTAUopLoopBegin", 16, 1, 0, 16)
T.call_extern("int32", "VTAUopLoopBegin", 16, 0, 1, 1)
T.tir.vta.uop_push(0, 0, 0, 0, 0, 0, 0, 0)
T.call_extern("int32", "VTAUopLoopEnd")
T.call_extern("int32", "VTAUopLoopEnd")
T.tir.vta.coproc_dep_push(2, 1)
T.tir.vta.coproc_dep_pop(2, 1)
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_scope", 2):
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_uop_scope", "VTAPushALUOp"):
T.call_extern("int32", "VTAUopLoopBegin", 16, 1, 1, 0)
T.tir.vta.uop_push(1, 0, 0, 0, 0, 3, 1, 8)
T.call_extern("int32", "VTAUopLoopEnd")
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_uop_scope", "VTAPushALUOp"):
T.call_extern("int32", "VTAUopLoopBegin", 16, 1, 1, 0)
T.tir.vta.uop_push(1, 0, 0, 0, 0, 1, 1, 0)
T.call_extern("int32", "VTAUopLoopEnd")
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_uop_scope", "VTAPushALUOp"):
T.call_extern("int32", "VTAUopLoopBegin", 16, 1, 1, 0)
T.tir.vta.uop_push(1, 0, 0, 0, 0, 0, 1, 127)
T.call_extern("int32", "VTAUopLoopEnd")
T.tir.vta.coproc_dep_push(2, 3)
T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_scope", 3)
T.tir.vta.coproc_dep_pop(2, 3)
for i1_inner in range(16):
T.call_extern("int32", "VTAStoreBuffer2D", T.tvm_thread_context(T.tir.vta.command_handle()), i1_inner, 4, res_1.data, i1_outer * 16 + i1_inner, 1, 1, 1)
T.tir.vta.coproc_dep_push(3, 2)
T.tir.vta.coproc_sync()
T.tir.vta.coproc_dep_pop(3, 2)
TVM Compilation and Verification¶
After specifying the schedule, we can compile it into a TVM function. We save the module so we can send it over RPC. We run the function and verify it against a numpy implementation to ensure correctness.
# Compile the TVM module
my_gemm = vta.build(
s, [data, weight, res], tvm.target.Target("ext_dev", host=env.target_host), name="my_gemm"
)
temp = utils.tempdir()
my_gemm.save(temp.relpath("gemm.o"))
remote.upload(temp.relpath("gemm.o"))
f = remote.load_module("gemm.o")
# Get the remote device context
ctx = remote.ext_dev(0)
# Initialize the data and weight arrays randomly in the int range of (-128, 128]
data_np = np.random.randint(-128, 128, size=(batch_size, in_channels)).astype(data.dtype)
weight_np = np.random.randint(-128, 128, size=(out_channels, in_channels)).astype(weight.dtype)
# Apply packing to the data and weight arrays from a 2D to a 4D packed layout
data_packed = data_np.reshape(
batch_size // env.BATCH, env.BATCH, in_channels // env.BLOCK_IN, env.BLOCK_IN
).transpose((0, 2, 1, 3))
weight_packed = weight_np.reshape(
out_channels // env.BLOCK_OUT, env.BLOCK_OUT, in_channels // env.BLOCK_IN, env.BLOCK_IN
).transpose((0, 2, 1, 3))
# Format the input/output arrays with tvm.nd.array to the DLPack standard
data_nd = tvm.nd.array(data_packed, ctx)
weight_nd = tvm.nd.array(weight_packed, ctx)
res_nd = tvm.nd.array(np.zeros(output_shape).astype(res.dtype), ctx)
# Clear stats
if env.TARGET in ["sim", "tsim"]:
simulator.clear_stats()
# Invoke the module to perform the computation
f(data_nd, weight_nd, res_nd)
# Verify against numpy implementation
res_ref = np.dot(data_np.astype(env.acc_dtype), weight_np.T.astype(env.acc_dtype))
res_ref = res_ref >> env.INP_WIDTH
res_ref = np.clip(res_ref, 0, inp_max)
res_ref = res_ref.astype(res.dtype)
res_ref = res_ref.reshape(
batch_size // env.BATCH, env.BATCH, out_channels // env.BLOCK_OUT, env.BLOCK_OUT
).transpose((0, 2, 1, 3))
np.testing.assert_equal(res_ref, res_nd.numpy())
# Print stats
if env.TARGET in ["sim", "tsim"]:
sim_stats = simulator.stats()
print("Execution statistics:")
for k, v in sim_stats.items():
print("\t{:<16}: {:>16}".format(k, v))
print("Successful blocked matrix multiply test!")
Execution statistics:
inp_load_nbytes : 4096
wgt_load_nbytes : 1048576
acc_load_nbytes : 0
uop_load_nbytes : 20
out_store_nbytes: 1024
gemm_counter : 4096
alu_counter : 192
Successful blocked matrix multiply test!
Summary¶
This tutorial demonstrates how TVM scheduling primitives can achieve computation blocking for a matrix multiplication example. This allows us to map arbitrarily large computation onto limited hardware accelerator resources.