Note
This tutorial can be used interactively with Google Colab! You can also click here to run the Jupyter notebook locally.

Deploy Single Shot Multibox Detector(SSD) model¶
Author: Yao Wang Leyuan Wang
This article is an introductory tutorial to deploy SSD models with TVM. We will use GluonCV pre-trained SSD model and convert it to Relay IR
import tvm
from tvm import te
from matplotlib import pyplot as plt
from tvm import relay
from tvm.contrib import graph_executor
from tvm.contrib.download import download_testdata
from gluoncv import model_zoo, data, utils
/venv/apache-tvm-py3.7/lib/python3.7/site-packages/gluoncv/check.py:8: DeprecationWarning: distutils Version classes are deprecated. Use packaging.version instead.
if LooseVersion(mx.__version__) < LooseVersion(mx_version) or \
/venv/apache-tvm-py3.7/lib/python3.7/site-packages/gluoncv/check.py:9: DeprecationWarning: distutils Version classes are deprecated. Use packaging.version instead.
LooseVersion(mx.__version__) >= LooseVersion(max_mx_version):
/venv/apache-tvm-py3.7/lib/python3.7/site-packages/gluoncv/check.py:30: DeprecationWarning: distutils Version classes are deprecated. Use packaging.version instead.
if LooseVersion(torch.__version__) < LooseVersion(torch_version) or \
/venv/apache-tvm-py3.7/lib/python3.7/site-packages/gluoncv/check.py:31: DeprecationWarning: distutils Version classes are deprecated. Use packaging.version instead.
LooseVersion(torch.__version__) >= LooseVersion(max_torch_version):
/venv/apache-tvm-py3.7/lib/python3.7/site-packages/gluoncv/__init__.py:40: UserWarning: Both `mxnet==1.6.0` and `torch==1.12.0+cpu` are installed. You might encounter increased GPU memory footprint if both framework are used at the same time.
warnings.warn(f'Both `mxnet=={mx.__version__}` and `torch=={torch.__version__}` are installed. '
Preliminary and Set parameters¶
Note
We support compiling SSD on both CPUs and GPUs now.
To get best inference performance on CPU, change target argument according to your device and follow the Auto-tuning a Convolutional Network for x86 CPU to tune x86 CPU and Auto-tuning a Convolutional Network for ARM CPU for arm CPU.
To get best inference performance on Intel graphics,
change target argument to opencl -device=intel_graphics.
But when using Intel graphics on Mac, target needs to
be set to opencl only for the reason that Intel subgroup
extension is not supported on Mac.
To get best inference performance on CUDA-based GPUs,
change the target argument to cuda; and for
OPENCL-based GPUs, change target argument to
opencl followed by device argument according
to your device.
supported_model = [
"ssd_512_resnet50_v1_voc",
"ssd_512_resnet50_v1_coco",
"ssd_512_resnet101_v2_voc",
"ssd_512_mobilenet1.0_voc",
"ssd_512_mobilenet1.0_coco",
"ssd_300_vgg16_atrous_voc" "ssd_512_vgg16_atrous_coco",
]
model_name = supported_model[0]
dshape = (1, 3, 512, 512)
Download and pre-process demo image
Convert and compile model for CPU.
block = model_zoo.get_model(model_name, pretrained=True)
def build(target):
mod, params = relay.frontend.from_mxnet(block, {"data": dshape})
with tvm.transform.PassContext(opt_level=3):
lib = relay.build(mod, target, params=params)
return lib
/venv/apache-tvm-py3.7/lib/python3.7/site-packages/mxnet/gluon/block.py:1389: UserWarning: Cannot decide type for the following arguments. Consider providing them as input:
data: None
input_sym_arg_type = in_param.infer_type()[0]
Downloading /workspace/.mxnet/models/ssd_512_resnet50_v1_voc-9c8b225a.zip from https://apache-mxnet.s3-accelerate.dualstack.amazonaws.com/gluon/models/ssd_512_resnet50_v1_voc-9c8b225a.zip...
0%| | 0/132723 [00:00<?, ?KB/s]
5%|4 | 6457/132723 [00:00<00:01, 64555.75KB/s]
11%|# | 14541/132723 [00:00<00:01, 74125.57KB/s]
17%|#7 | 22584/132723 [00:00<00:01, 77002.52KB/s]
23%|##3 | 30612/132723 [00:00<00:01, 78294.66KB/s]
29%|##9 | 38649/132723 [00:00<00:01, 79039.49KB/s]
35%|###5 | 46553/132723 [00:00<00:01, 78975.48KB/s]
41%|####1 | 54619/132723 [00:00<00:00, 79521.24KB/s]
47%|####7 | 62721/132723 [00:00<00:00, 79996.31KB/s]
53%|#####3 | 70817/132723 [00:00<00:00, 80293.85KB/s]
59%|#####9 | 78847/132723 [00:01<00:00, 80269.78KB/s]
66%|######5 | 86990/132723 [00:01<00:00, 80619.81KB/s]
72%|#######1 | 95071/132723 [00:01<00:00, 80675.10KB/s]
78%|#######7 | 103249/132723 [00:01<00:00, 81005.19KB/s]
84%|########3 | 111350/132723 [00:01<00:00, 80907.17KB/s]
90%|######### | 119477/132723 [00:01<00:00, 81012.32KB/s]
96%|#########6| 127579/132723 [00:01<00:00, 80864.64KB/s]
100%|##########| 132723/132723 [00:01<00:00, 79718.08KB/s]
Create TVM runtime and do inference .. note:
Use target = "cuda -libs" to enable thrust based sort, if you
enabled thrust during cmake by -DUSE_THRUST=ON.
def run(lib, dev):
# Build TVM runtime
m = graph_executor.GraphModule(lib["default"](dev))
tvm_input = tvm.nd.array(x.asnumpy(), device=dev)
m.set_input("data", tvm_input)
# execute
m.run()
# get outputs
class_IDs, scores, bounding_boxs = m.get_output(0), m.get_output(1), m.get_output(2)
return class_IDs, scores, bounding_boxs
for target in ["llvm", "cuda"]:
dev = tvm.device(target, 0)
if dev.exist:
lib = build(target)
class_IDs, scores, bounding_boxs = run(lib, dev)
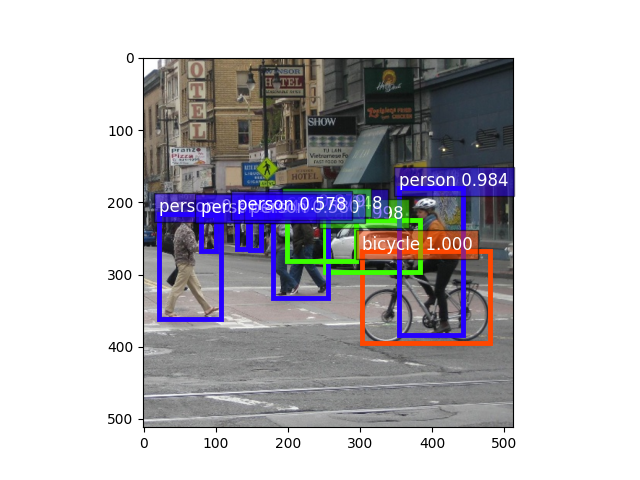
Display result
ax = utils.viz.plot_bbox(
img,
bounding_boxs.numpy()[0],
scores.numpy()[0],
class_IDs.numpy()[0],
class_names=block.classes,
)
plt.show()
Total running time of the script: ( 3 minutes 27.363 seconds)